1. 单向链表
定义:由节点构成,每个节点包含数据和指向下一节点的指针,方向单向。
优点:
动态内存分配,无需预知长度。
插入/删除高效(时间复杂度
O(1),若已知位置)。
缺点:
随机访问需遍历(
O(n))。存储指针增加内存开销。
应用场景:频繁插入/删除且无需随机访问的场景,如链式缓存、简单任务队列。
2. 双向链表
定义:每个节点含指向前驱和后继的指针。
优点:
双向遍历,删除/插入前驱节点更高效。
缺点:
内存开销更大(每个节点多一个指针)。
操作需维护双向指针,逻辑稍复杂。
Java实现:
LinkedList。应用场景:需双向操作的数据,如浏览器历史记录、LRU缓存。
3. 队列(Queue)
特性:先进先出(FIFO)。
实现:
ArrayDeque:基于动态数组的双端队列,支持队列和栈操作(
offer/poll或push/pop)。PriorityQueue:基于小顶堆(数组存储完全二叉树),元素按优先级出队,插入/删除
O(log n)。限制:不允许
null元素。
应用场景:任务调度(如线程池)、带优先级的处理(如急诊排队)。
4. 栈(Stack)
特性:后进先出(LIFO)。
Java实现:推荐
ArrayDeque替代遗留的Stack类。操作:
push(压栈)、pop(弹栈)、peek(查看栈顶)。应用场景:函数调用栈、括号匹配、表达式求值。
5. 二叉树
定义:每个节点最多两个子节点。
遍历方式:
前序:根 → 左 → 右(用于复制树结构)。
中序:左 → 根 → 右(二叉搜索树有序输出)。
后序:左 → 右 → 根(用于释放树内存)。
层序:按层级遍历(广度优先,使用队列)。
特殊类型:二叉搜索树(BST)、平衡二叉树(AVL)、红黑树。
应用场景:数据库索引、文件系统目录结构。
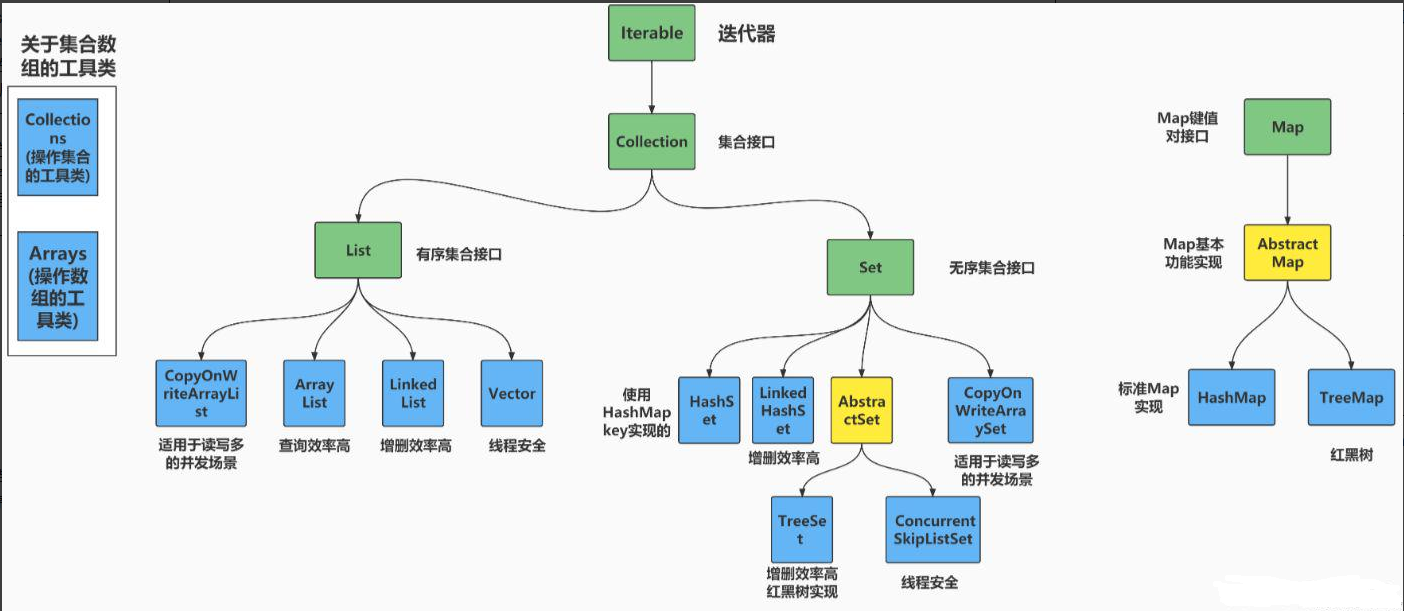
6. 集合(Set)
特性:元素唯一、无序(数学定义)。
Java实现:
HashSet:基于哈希表,O(1)查询,无序。LinkedHashSet:维护插入顺序的哈希表。TreeSet:基于红黑树,元素有序(O(log n)操作)。
应用场景:去重、成员存在性检查。
图解
7. B树家族
8. 图(Graph)
组成:顶点(Vertex)和边(Edge)。
类型:
有向图/无向图。
带权图(如最短路径问题)。
存储方式:
邻接矩阵(适合稠密图)。
邻接表(适合稀疏图,节省空间)。
算法:DFS、BFS、Dijkstra、Prim、Kruskal等。
应用场景:社交网络、路由规划、推荐系统。
总结对比
通过结构化对比和场景分析,可更高效地根据需求选择数据结构。